Combining and Transforming Random Variables
Suppose \(x\) is a Gaussian random variable, with mean \(\mu_x\) and uncertainty \(\sigma_x\) .
For example, it could represent our degree of confidence in the flux of a star. What is the
uncertainty on some transformation \(y = f(x)\)? A relevant example would be to calculate the
error on a magnitude, given the error on a measured flux. We can approximate \(f(x)\) with a
Taylor expansion around \(\mu_x\),
\[f(x) \approx f(\mu_x) + \frac{df}{dx} \bigg|_{x=\mu_x} (x-\mu_x) + \ldots.\]
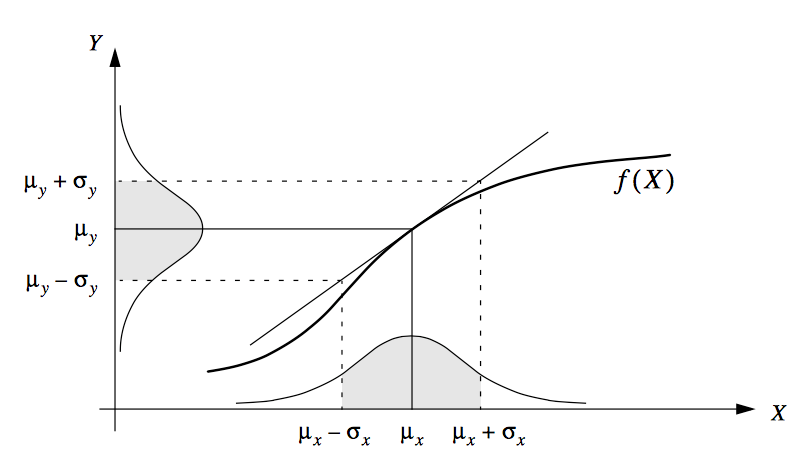
This approximation is shown below in figure 55. Because \(f(\mu_x)\) and \(
\frac{df}{dx} \big|_{x=\mu_x} \) are just numbers, under this approximation, \(y\) is also a
Gaussian random variable, and we can calculate its mean and standard deviation to work out the
uncertainty on \(y\).
The mean is straightforward, since \(\mu_y = f(\mu_x)\). To calculate the standard deviation,
inspection of figure 55 shows that
\[\mu_y + \sigma_y = f (\mu_x + \sigma_x).\]
Using the Taylor expansion approximation we have
\begin{align}
\sigma_y &= f(\mu_x + \sigma_x) - \mu_y \\
&= f(\mu_x) + \frac{df}{dx} (\mu_x + \sigma_x - \mu_x) - \mu_y \\
&= \mu_y + \frac{df}{dx} \sigma_x - \mu_y \\
\sigma_y &= \frac{df}{dx} \sigma_x
\end{align}
It is vital to note that this is an approximation! You can see from figure 55 that if \(\sigma_x\) is large, the Taylor series becomes a poor approximation and the error
bars will be incorrect. More seriously, \(y\) doesn't have a Gaussian PDF under a general
transformation! A classic example of this is converting magnitudes to fluxes when the error is
large.
Functions of multiple variables
We now look at the general case \(y = f(x_1,x_2,x_3,\ldots,x_n)\), where \(x_i\) is a Gaussian
random variable. For example, \(x_i\) might be the number of counts in pixel \(i\), and we want
to work out the error on the total number of counts from a star, \(y = \sum_i^N x_i\).
The formal derivation of the uncertainty on \(y\) is not straightforward, but we can get an idea
by considering the contribution from each \(x_i\) in turn. From above, the uncertainty on \(y\)
caused by uncertainty in \(x_i\) alone can be written
\[\sigma_{y,i} = \frac{\partial f}{\partial x_i} \sigma_{x_i}.\]
How are we to combine the contributions from each \(x_i\)? If we simply add them, a positive
error may cancel with a negative error. This concept is obviously wrong - it's like saying that
two uncertainties can somehow cancel and make an experiment more accurate. I hope it is
intuitive that we should add the contributions in quadrature, e.g
\[\sigma_y^2 = \left( \frac{\partial f}{\partial x_1} \right) ^2 \sigma_{x_1}^2 + \left(
\frac{\partial f}{\partial x_2} \right) ^2 \sigma_{x_2}^2 + \ldots + \left( \frac{\partial
f}{\partial x_n}\right) ^2 \sigma_{x_n} ^2= \sum_i^n \left( \frac{\partial f}{\partial
x_i}\right) ^2 \sigma_{x_i}^2 \]
This is known as the equation for error propagation.
Some worked examples
The equation for error propagation looks like a nightmare. However, it is not as bad as it looks.
Let us look at a few familiar examples to show that it produces the results we expect, before
moving on to examples more relevant to astronomy.
Sums of two variables
Suppose we measure \(x\) and \(y\), each with uncertainties \(\sigma_x\) and \(\sigma_y\). Whats
the uncertainty in \(z = x + y\)? From the equation of error propagation
\begin{align}
\sigma_z^2 &= \left( \frac{\partial z}{\partial x} \right) ^2 \sigma_x^2 + \left( \frac{\partial
z}{\partial y} \right) ^2 \sigma_y^2 \\
\sigma_z^2 &= \sigma_x^2 + \sigma_y^2,
\end{align}
as you might expect if you have covered error propagation using simple rules.
Sums of two variables
What is the uncertainty in \(z = xy\). Again, the equation of error propagation gives
\begin{align}
\sigma_z^2 &= \left( \frac{\partial z}{\partial x} \right) ^2 \sigma_x^2 + \left( \frac{\partial
z}{\partial y} \right) ^2 \sigma_y^2 \\
\sigma_z^2 &= y^2 \sigma_x^2 + x^2 \sigma_y^2, \\
\end{align}
which we divide by \(z^2 = x^2y^2\) to get
\[ \left( \frac{\sigma_z}{z} \right) ^2 = \left( \frac{\sigma_x}{x} \right) ^2 + \left(
\frac{\sigma_y}{y}\right) ^2,\]
again, as we expect.
Error on the mean
Suppose we obtain \(N\) measurements of a single value \(x_i\), each with an uncertainty of
\(\sigma_x\). We calculate the mean \(z = \sum_i^N x_i / N\). What is the error on the mean?
Since \(z = \frac{x_1}{N} + \frac{x_2}{N} + \ldots + \frac{x_N}{N}\), then
\[ \frac{\partial z}{\partial x_i} = \frac{1}{N} .\]
Therefore, the error propagation equation gives
\[ \sigma_z^2 = \sum_i^N \frac{1}{N^2} \sigma_x^2 = \frac{N}{N^2} \sigma_x^2 =
\frac{\sigma_x^2}{N},\]
which can be re-written
\[\sigma_z = \sigma_x / \sqrt{N}.\]
Looking at the examples above, you can see that the equation of error propagation can be used to
derive all the error rules you may have learned previously. It is more useful to remember the
equation than these rules, since it can be applied to any combination of random variables. We
will illustrate this shortly. but first I want to show an example of how we might use errors in
practice.
Comparing measured experimental results
This is a particularly important example, because it is related to comparing two measurements of
the same quantity, as measured by experiment. Suppose experiment \(A\) measures Hubble's
constant to be \(H_0 = 63.4 \pm 0.5\) km/s/Mpc, but experiment \(B\) measures it to be \(H_0 =
73.5 \pm 1.4\) km/s/Mpc. Do they disagree? Well, there are two options: either the experiments
are finding different values for \(H_0\), or they are actually measuring the same value, and the
reported numbers disagree purely because they are random variables, and so move
around a bit by
chance.
Well, we can calculate the difference \(\Delta\)
between the two measurements \(\Delta = B-A = 10.1\) km/s/Mpc. We can also calculate the
uncertainty \( \sigma_{\Delta} = \sqrt{\sigma_A^2 + \sigma_B^2} = 1.5 \). We can write that \(
\Delta = 10.1 \pm 1.5 \) km/s/Mpc. But recall that this is shorthand for saying that our
confidence in the true value of \(\Delta\) is represented by a Gaussian of mean 10.1 and a
standard deviation of 1.5. The mean of this Gaussian is 6.7 standard deviations away from
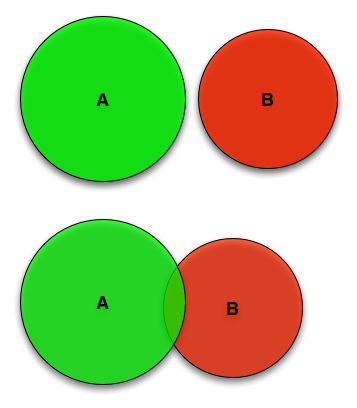
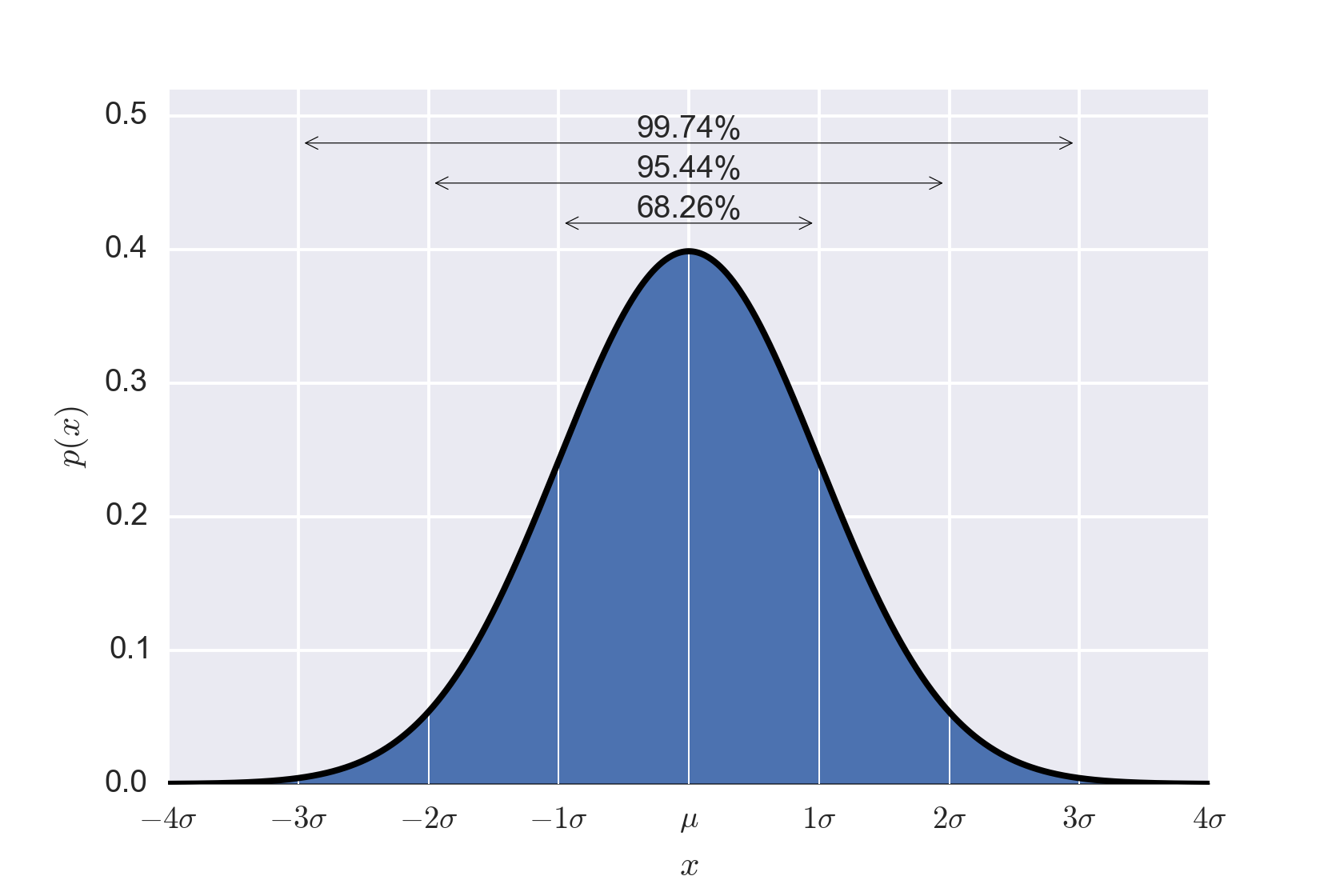
zero - which is the value we'd expect if there was no disagreement. As seen in figure 53, values 6.7 standard deviations from the mean are highly unlikely to
happen by chance. We therefore conclude the values disagree